6.6. Natural Language Processing#
This section some tools to process and work with text.
6.6.1. TextBlob: Processing Text in One Line of Code#
Show code cell content
!pip install textblob
Show code cell content
!python -m textblob.download_corpora
TextBlob offers quick text analysis, such as sentiment detection, tokenization, noun phrase extraction, word frequency analysis, and spelling correction. Start by creating a TextBlob instance:
from textblob import TextBlob
text = "Today is a beautiful day"
blob = TextBlob(text)
Tokenize words:
blob.words
WordList(['Today', 'is', 'a', 'beautiful', 'day'])
Extract noun phrases:
blob.noun_phrases
WordList(['beautiful day'])
Analyze sentiment:
blob.sentiment
Sentiment(polarity=0.85, subjectivity=1.0)
Count words:
blob.word_counts
defaultdict(int, {'today': 1, 'is': 1, 'a': 1, 'beautiful': 1, 'day': 1})
Correct spelling:
text = "Today is a beutiful day"
blob = TextBlob(text)
blob.correct()
TextBlob("Today is a beautiful day")
6.6.2. Convert Names into a Generalized Format#
Show code cell content
!pip install mlxtend
Names collected from different sources might have different formats. To convert names into the same format for further processing, use mlxtend’s generalize_names.
from mlxtend.text import generalize_names
generalize_names("Tran, Khuyen")
'tran k'
generalize_names("Khuyen Tran")
'tran k'
generalize_names("Khuyen Tran", firstname_output_letters=2)
'tran kh'
6.6.3. sumy: Summarize Text in One Line of Code#
Show code cell content
!pip install sumy
Sumy is an easy-to-use tool for text summarization, offering 7 different methods. To summarize the article “How to Learn Data Science (Step-By-Step)” from DataQuest:
$ sumy lex-rank --length=10 --url=https://www.dataquest.io/blog/learn-data-science/
!sumy lex-rank --length=10 --url=https://www.dataquest.io/blog/learn-data-science/
So how do you start to learn data science?
If I had started learning data science this way, I never would have kept going.
I learn when I’m motivated, and when I know why I’m learning something.
There’s some science behind this, too.
If you want to learn data science or just pick up some data science skills, your first goal should be to learn to love data.
But it’s important to find that thing that makes you want to learn.
By working on projects, you gain skills that are immediately applicable and useful, because real-world data scientists have to see data science projects through from start to finish, and most of that work is in fundamentals like cleaning and managing the data.
And so on, until the algorithm worked well.
Find people to work with at meetups.
For more information on these, you can take a look at our Data Scientist learning path , which is designed to teach all of the important data science skills for Python learners.
6.6.4. Spacy_streamlit: Create a Web App to Visualize Your Text in 3 Lines of Code#
Show code cell content
!pip install spacy-streamlit
To quickly create an app to visualize the structure of a text, use spacy_streamlit.
To understand how to use spacy_streamlit, we add the code below to a file called streamlit_app.py:
%%writefile streamlit_app.py
import spacy_streamlit
models = ["en_core_web_sm"]
text = "Today is a beautiful day"
spacy_streamlit.visualize(models, text)
On your terminal, type:
$ streamlit run streamlit_app.py
Output:
Show code cell content
!python -m spacy download en_core_web_sm
Show code cell source
!streamlit run streamlit_app.py
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://192.168.1.90:8501
^C
Stopping...
Click the URL and you should see something like below:
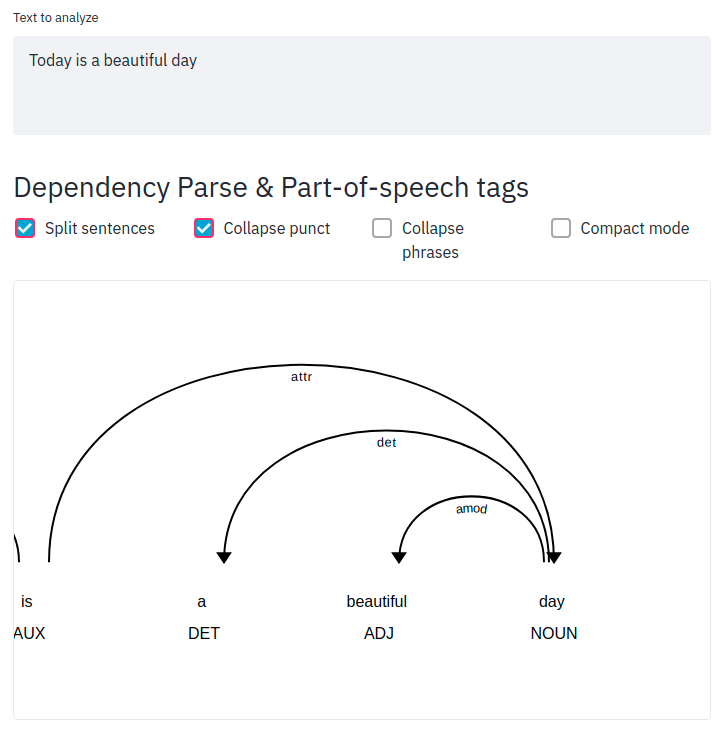
6.6.5. textacy: Extract a Contiguous Sequence of Words#
Show code cell content
!pip install spacy textacy
Show code cell content
!python -m spacy download en_core_web_sm
To extract sequences of words (n-grams), use the textacy library:
import spacy
from textacy.extract import ngrams
nlp = spacy.load("en_core_web_sm")
text = nlp("Ice cream is a soft frozen food made with sweetened and flavored milk fat.")
# extract sequences of 3 words
[n.text for n in ngrams(text, n=3)]
['soft frozen food', 'sweetened and flavored', 'flavored milk fat']
6.6.6. Num2Words: Convert Number to Words#
Show code cell content
!pip install num2words
The num2words library helps convert numerical values into words, making NLP tasks like matching numeric data to their textual equivalents easier:
from num2words import num2words
num2words(2019)
'two thousand and nineteen'
num2words(2019, to="ordinal")
'two thousand and nineteenth'
num2words(2019, to="ordinal_num")
'2019th'
num2words(2019, to="year")
'twenty nineteen'
It also supports multiple languages:
num2words(2019, lang="vi")
'hai nghìn lẻ mười chín'
num2words(2019, lang="es")
'dos mil diecinueve'
6.6.7. Numerizer: Standardizing Numerical Data in Text#
Show code cell content
!pip install numerizer
Converting textual numbers to numeric values is challenging due to diverse language representations.
Numerizer simplifies this process by turning various text formats into corresponding numbers.
from numerizer import numerize
numerize("four hundred and sixty two")
'462'
numerize("four hundred sixty two")
'462'
numerize("four sixty two")
'462'
numerize("four sixty-two")
'462'
6.6.8. Preprocess Text in One Line of Code with Texthero#
import warnings
warnings.simplefilter("ignore", FutureWarning)
Show code cell content
!pip install -U texthero==1.0.5
Cleaning text data is often cumbersome and requires multiple steps such as removing punctuation, stopwords, diacritics, and extra spaces.
To demonstrate this, create example text data:
import re
import pandas as pd
from nltk.corpus import stopwords
from unidecode import unidecode
# Example text data
data = {
"text": [
"This sèntencé (123 /) needs to [OK!] be cleaned! ",
"Texthero simplifies text preprocessing tasks!!!",
"Extra spaces and punctuations, must be removed...",
]
}
df = pd.DataFrame(data)
print(df)
text
0 This sèntencé (123 /) needs to [OK!] be cleane...
1 Texthero simplifies text preprocessing ...
2 Extra spaces and punctuations, must be remo...
Cleaning this dataset typically involves using multiple libraries and functions, leading to longer, repetitive code:
## Text preprocessing without Texthero
def preprocess_text(text):
text = re.sub(r"[^\w\s]", "", text) # Remove punctuation
text = " ".join(
[
word
for word in text.split()
if word.lower() not in stopwords.words("english")
]
) # Remove stopwords
text = unidecode(text) # Remove diacritics
text = re.sub(r"\s+", " ", text).strip() # Remove extra spaces
text = text.lower() # Convert text to lowercase
return text
df["processed_text"] = df["text"].apply(preprocess_text)
print(df["processed_text"])
0 sentence 123 needs ok cleaned
1 texthero simplifies text preprocessing tasks
2 extra spaces punctuations must removed
Name: processed_text, dtype: object
To clean text data in one line of code, use texthero.clean:
import texthero as hero
## Clean text data
df["cleaned_text"] = hero.clean(df["text"])
print(df["cleaned_text"])
0 sentence 123 needs ok cleaned
1 texthero simplifies text preprocessing tasks
2 extra spaces punctuations must removed
Name: cleaned_text, dtype: object
Texthero also allows users to tailor text preprocessing according to specific project needs while maintaining simplicity:
## Custom cleaning pipeline
df["custom_cleaned_text"] = (
df["text"]
.pipe(hero.remove_digits) # Remove digits
.pipe(hero.remove_punctuation) # Remove punctuation
.pipe(hero.remove_diacritics) # Remove diacritics
.pipe(hero.remove_whitespace) # Remove extra spaces
)
print(df["custom_cleaned_text"])
0 This sentence 123 needs to OK be cleaned
1 Texthero simplifies text preprocessing tasks
2 Extra spaces and punctuations must be removed
Name: custom_cleaned_text, dtype: object
6.6.9. texthero: Reduce Dimension and Visualize Text in One Line of Code#
Show code cell content
!pip install 'gensim==3.6.0'
!pip install 'texthero==1.1.0'
!pip install unidecode
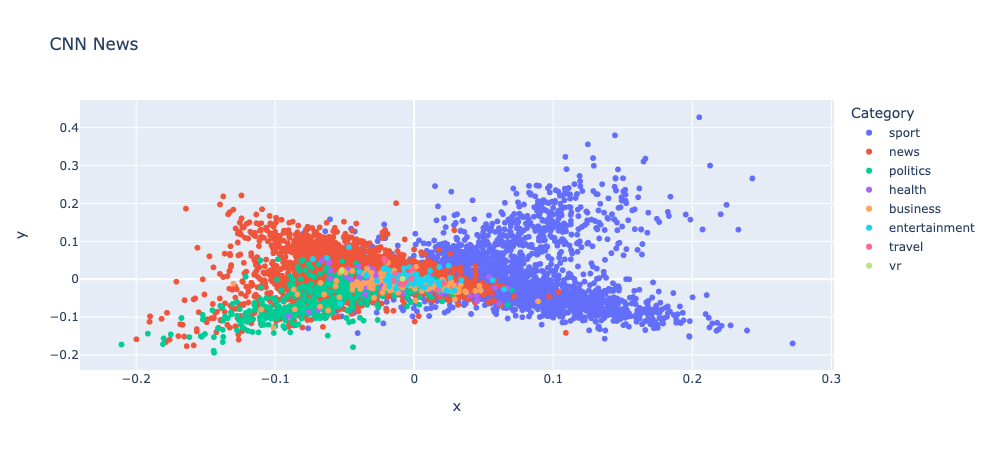
To visualize text data in 2D, typically, you need to clean, encode, and reduce the dimensions of your text, which can be tedious. Texthero simplifies this process into just two lines of code.
Below is an example using descriptions from CNN news articles. Each point represents an article, colored by its category.
import pandas as pd
import texthero as hero
df = pd.read_csv("small_CNN.csv")
df["pca"] = df["Description"].pipe(hero.clean).pipe(hero.tfidf).pipe(hero.pca)
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 8))
hero.scatterplot(df, col="pca", color="Category", title="CNN News")
<Figure size 1000x300 with 0 Axes>
6.6.10. wordfreq: Estimate the Frequency of a Word in 36 Languages#
Show code cell content
!pip install wordfreq
If you need to check the frequency of a word in 36 different languages, wordfreq is an excellent tool.
It even covers words that occur as infrequently as once per 10 million words.
import matplotlib.pyplot as plt
import seaborn as sns
from wordfreq import word_frequency
word_frequency("eat", "en")
0.000135
word_frequency("the", "en")
0.0537
sentence = "There is a dog running in a park"
words = sentence.split(" ")
word_frequencies = [word_frequency(word, "en") for word in words]
sns.barplot(words, word_frequencies)
plt.show()
/home/khuyen/book/venv/lib/python3.8/site-packages/seaborn/_decorators.py:36: FutureWarning: Pass the following variables as keyword args: x, y. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation.
warnings.warn(
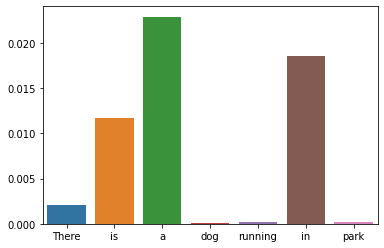
6.6.11. newspaper3k: Extract Meaningful Information From an Articles in 2 Lines of Code#
Show code cell content
!pip install newspaper3k nltk
To quickly extract meaningful information from an article in a few lines of code, use newspaper3k.
import nltk
from newspaper import Article
nltk.download("punkt")
url = "https://mathdatasimplified.com/2023/05/08/build-an-efficient-data-pipeline-is-dbt-the-key/"
article = Article(url)
article.download()
article.parse()
article.title
'What is dbt (data build tool) and When should you use it?'
print(article.publish_date)
2023-05-08 00:00:00
article.top_image
'https://mathdatasimplified.com/wp-content/uploads/2023/05/dbt-pros-and-cons-6.png'
article.nlp()
print(article.summary)
One tool that has gained popularity in recent years for managing data pipelines is dbt (data build tool).
When Should You Consider dbtYou should consider using dbt when:You have a data warehouse: dbt is an effective tool for organizing, transforming, and testing data in a data warehouse environment.
Your data changes frequently: dbt’s snapshot allows you to track changes in data over time.
Other tools are needed for tasks such as data extraction, data cleansing, and data loading.
You want to visualize your data: dbt is not a data visualization tool.
article.keywords
['tool',
'changes',
'build',
'dbt',
'model',
'documentation',
'sql',
'data',
'select',
'models',
'property_type']
6.6.12. Questgen.ai: Question Generator in Python#
Show code cell content
!pip install git+https://github.com/ramsrigouthamg/Questgen.ai
!pip install git+https://github.com/boudinfl/pke.git
!python -m nltk.downloader universal_tagset
!python -m spacy download en
Show code cell content
!wget https://github.com/explosion/sense2vec/releases/download/v1.0.0/s2v_reddit_2015_md.tar.gz
!tar -xvf s2v_reddit_2015_md.tar.gz
Generating questions manually from a document can be time-consuming. Questgen.ai automates this task, allowing you to quickly generate Boolean or FAQ-style questions.
from pprint import pprint
import nltk
nltk.download("stopwords")
from Questgen import main
payload = {
"input_text": """The weather today was nice so I went for a walk. I stopped for a quick chat with my neighbor.
It turned out that my neighbor just got a dog named Pepper. It is a black Labrador Retriever."""
}
qe = main.BoolQGen()
output = qe.predict_boolq(payload)
pprint(output)
{'Boolean Questions': ['Is there a dog in my neighborhood?',
"Is pepper my neighbor's dog?",
'Is pepper the same as a labrador?'],
'Count': 4,
'Text': 'The weather today was nice so I went for a walk. I stopped for a '
'quick chat with my neighbor.\n'
' It turned out that my neighbor just got a dog named Pepper. It '
'is a black Labrador Retriever.'}
output = qg.predict_shortq(payload)
pprint(output)
Running model for generation
{'questions': [{'Question': 'What was the purpose of the stop?', 'Answer': 'chat', 'id': 1, 'context': 'I stopped for a quick chat with my neighbor.'}, {'Question': 'Who got a dog named Pepper?', 'Answer': 'neighbor', 'id': 2, 'context': 'It turned out that my neighbor just got a dog named Pepper. I stopped for a quick chat with my neighbor.'}]}
{'questions': [{'Answer': 'chat',
'Question': 'What was the purpose of the stop?',
'context': 'I stopped for a quick chat with my neighbor.',
'id': 1},
{'Answer': 'neighbor',
'Question': 'Who got a dog named Pepper?',
'context': 'It turned out that my neighbor just got a dog '
'named Pepper. I stopped for a quick chat with my '
'neighbor.',
'id': 2}],
'statement': 'The weather today was nice so I went for a walk. I stopped for '
'a quick chat with my neighbor. It turned out that my neighbor '
'just got a dog named Pepper. It is a black Labrador Retriever.'}
6.6.13. Word Ninja: Slice Your Lumped-Together Words#
Show code cell content
!pip install wordninja
Want to split compound words? Word Ninja is surprisingly effective at doing just that. Here are a few examples:
import wordninja
wordninja.split("honeyinthejar")
['honey', 'in', 'the', 'jar']
wordninja.split("ihavetwoapples")
['i', 'have', 'two', 'apples']
wordninja.split("aratherblusterday")
['a', 'rather', 'bluster', 'day']
6.6.14. textstat: Calculate Statistics From Text#
Show code cell content
!pip install textstat
To analyze text statistics such as readability scores and reading time, use the textstat library.
To calculate the Automated Readability Index (ARI), which indicates the grade level required to understand a text, use automated_readability_index. For example, an ARI of 10.8 means the text is suitable for 10th to 11th graders.
import textstat
text = "The working memory system is a form of conscious learning. But not all learning is conscious. Psychologists have long marveled at children’s ability to acquire perfect pronunciation in their first language or recognize faces."
textstat.automated_readability_index(text)
10.8
You can also measure the reading time of a text in seconds using reading_time:
textstat.reading_time(text, ms_per_char=14.69)
2.82
6.6.15. Accelerate String Matching with RapidFuzz#
Show code cell content
!pip install rapidfuzz
String matching and comparison are essential tasks in data cleaning and processing. Traditional exact matching often fails to capture similar entries due to typos or inconsistent formatting:
companies = ["Apple Inc.", "Microsoft Corp.", "Google LLC"]
search_term = "apple incorporated"
## Traditional exact matching
matches = [company for company in companies if company.lower() == search_term.lower()]
print(f"Exact matches: {matches}") # Returns empty list
Exact matches: []
RapidFuzz provides powerful fuzzy string matching capabilities. Let’s see how to use them effectively:
from rapidfuzz import fuzz, process
## Compare two strings
similarity = fuzz.ratio("Apple Inc.", "APPLE INC")
print(f"Similarity score: {similarity:.3f}")
Similarity score: 31.579
## Sample company names with variations
companies = [
"Apple Inc.",
"Apple Incorporated",
"APPLE INC",
"Microsoft Corporation",
"Microsoft Corp.",
"Google LLC",
"Alphabet Inc.",
]
## Find best matches for "apple incorporated"
matches = process.extract("apple incorporated", companies, scorer=fuzz.WRatio, limit=2)
print("Best matches:")
for match in matches:
print(f"Match: {match[0]}, Score: {match[1]:.3f}")
Best matches:
Match: Apple Incorporated, Score: 88.889
Match: Apple Inc., Score: 66.316
6.6.16. Checklist: Create Data to Test Your NLP Model#
Show code cell content
!pip install checklist torch
It can be time-consuming to create data to test edge cases of your NLP model. To quickly create data to test your NLP models, use Checklist.
In the code below, I use Checklist’s Editor to create multiple examples of negation in one line of code.
import checklist
from checklist.editor import Editor
editor = Editor()
editor.template("{mask} is not {a:pos} option.", pos=["good", "cool"], nsamples=5).data
['that is not a good option.',
'War is not a cool option.',
'Windows is not a good option.',
'Facebook is not a cool option.',
'Sleep is not a cool option.']
editor.template("{mask} is not {a:neg} option.", neg=["bad", "awful"], nsamples=5).data
['There is not a bad option.',
'Closure is not an awful option.',
'TPP is not a bad option.',
'Security is not an awful option.',
'Change is not an awful option.']
6.6.17. Top2Vec: Quick Topic Modeling in Python#
!pip install top2vec
Manually identifying topics from large text collections and having to specify the number of topics beforehand results in subjective, inconsistent topic modeling and requires significant trial and error.
Top2Vec automatically discovers topics by finding dense clusters of semantically similar documents and identifying the words that attract those documents together.
In this example, we will use the Top2Vec library to detect topics in a dataset of fake news articles.
Load the “Fake-News” dataset from OpenML:
from sklearn.datasets import fetch_openml
from top2vec import Top2Vec
news = fetch_openml("Fake-News")
text = news.data["text"].to_list()
Create a Top2Vec model with the text data, using the “learn” speed and 8 worker threads:
model = Top2Vec(documents=text, speed="learn", workers=8)
2025-02-17 16:39:25,565 - top2vec - INFO - Pre-processing documents for training
/Users/khuyentran/book/venv/lib/python3.11/site-packages/sklearn/feature_extraction/text.py:517: UserWarning: The parameter 'token_pattern' will not be used since 'tokenizer' is not None'
warnings.warn(
2025-02-17 16:39:33,112 - top2vec - INFO - Downloading all-MiniLM-L6-v2 model
2025-02-17 16:39:37,713 - top2vec - INFO - Creating joint document/word embedding
2025-02-17 16:41:08,069 - top2vec - INFO - Creating lower dimension embedding of documents
/Users/khuyentran/book/venv/lib/python3.11/site-packages/sklearn/utils/deprecation.py:151: FutureWarning: 'force_all_finite' was renamed to 'ensure_all_finite' in 1.6 and will be removed in 1.8.
warnings.warn(
2025-02-17 16:41:12,858 - top2vec - INFO - Finding dense areas of documents
/Users/khuyentran/book/venv/lib/python3.11/site-packages/sklearn/utils/deprecation.py:151: FutureWarning: 'force_all_finite' was renamed to 'ensure_all_finite' in 1.6 and will be removed in 1.8.
warnings.warn(
/Users/khuyentran/book/venv/lib/python3.11/site-packages/sklearn/utils/deprecation.py:151: FutureWarning: 'force_all_finite' was renamed to 'ensure_all_finite' in 1.6 and will be removed in 1.8.
warnings.warn(
2025-02-17 16:41:13,014 - top2vec - INFO - Finding topics
Get the number of topics detected by the model:
model.get_num_topics()
72
In this example, Top2Vec automatically determines the number and content of topics by analyzing document similarities in the embedding space
Get the topics in decreasing size:
topic_words, word_scores, topic_nums = model.get_topics(72)
print("\nSecond Topic - Top 5 Words and Scores:")
for word, score in zip(topic_words[1][:5], word_scores[1][:5]):
print(f"Word: {word:<20} Score: {score:.4f}")
Second Topic - Top 5 Words and Scores:
Word: clinton Score: 0.5632
Word: sanders Score: 0.5249
Word: hillary Score: 0.5232
Word: clintons Score: 0.4884
Word: dnc Score: 0.4661
print(f"Second Topic - Top 5 Words: {topic_words[1][:5]}")
Second Topic - Top 5 Words: ['clinton' 'sanders' 'hillary' 'clintons' 'dnc']
Search for topics most similar to the keyword “president”:
topic_words, word_scores, topic_scores, topic_nums = model.search_topics(
keywords=["president"], num_topics=2
)
first_five_words = [topic[:5] for topic in topic_words]
print("Topics most similar to president:")
for topic_num, words in zip(topic_nums, first_five_words):
print(f"Topic {topic_num}: {words}")
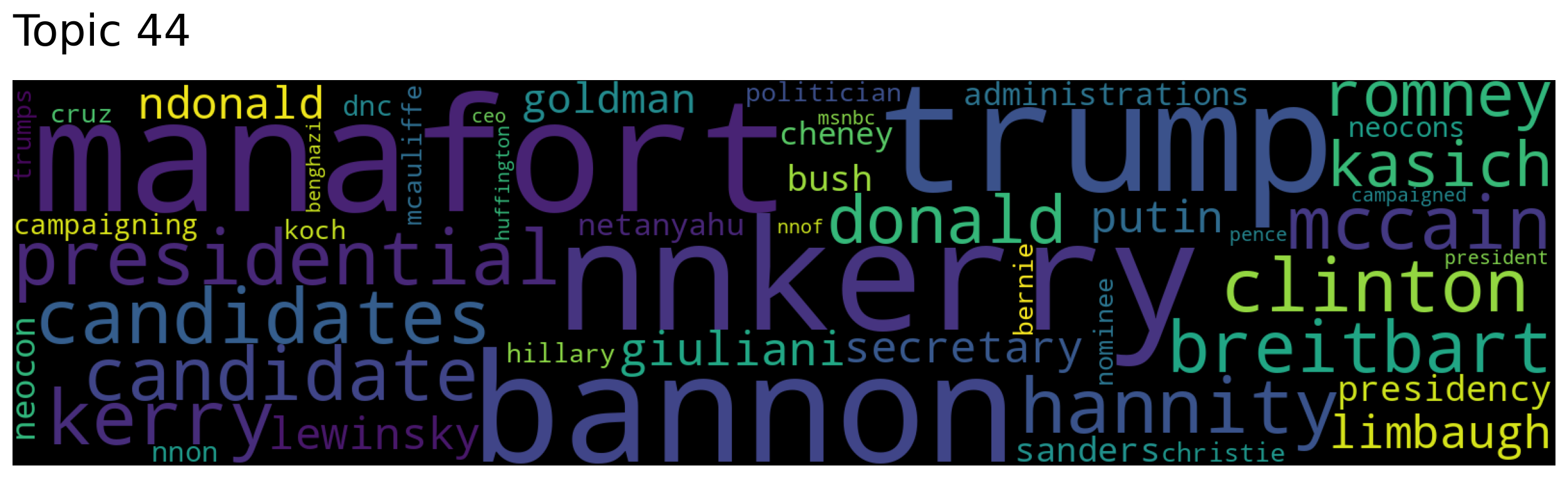
Topics most similar to president:
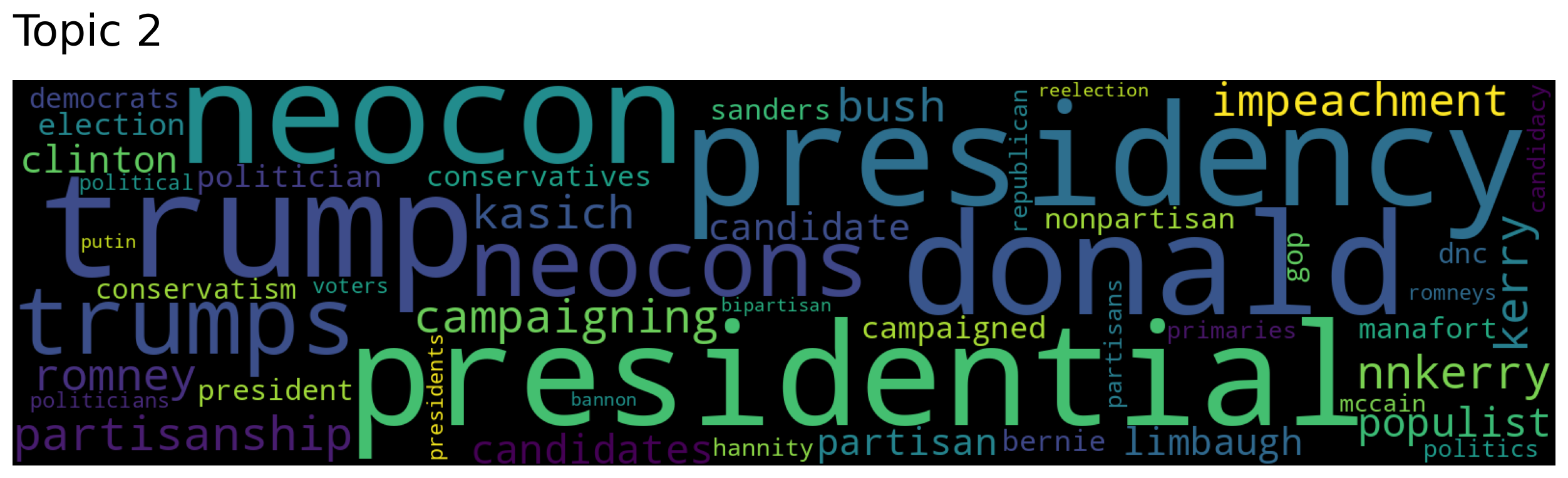
Topic 44: ['manafort' 'nnkerry' 'trump' 'bannon' 'presidential']
Topic 2: ['trump' 'presidential' 'neocon' 'presidency' 'donald']
Generate word clouds for the topics most similar to “president”:
for topic in topic_nums:
model.generate_topic_wordcloud(topic)
6.6.18. Expanding English Contractions in Text#
Show code cell content
!pip install contractions
Contraction can cause issues when processing text. To expand contractions using Python, use the library contractions
import contractions
sent = "I'm not sure, but I'd like to do it"
contractions.fix(sent)
'I am not sure, but I would like to do it'
6.6.19. inflect: Generate Plurals, Singulars, and Indefinite Articles#
Show code cell content
!pip install inflect
To generate plurals, singulars, or indefinite articles from given words, use inflect.
import inflect
p = inflect.engine()
p.plural_noun("he")
'they'
p.plural_verb("sees")
'see'
p.gender("feminine")
p.singular_noun("they")
'she'
if p.compare_verbs("sees", "see"):
print("same word")
same word
## Add the correct "a" or "an" for a given word
fruit1 = "apple"
fruit2 = "banana"
print(f"I got you {p.a(fruit1)} " f"and {p.a(fruit2)}")
I got you an apple and a banana
6.6.21. Chroma: The Lightning-Fast Solution to Text Embeddings and Querying#
Show code cell content
!pip install chromadb
Semantic search uses embedding to understand the meaning of search queries instead of relying solely on keyword matches to locate documents.
Embedding is like a translator converting words into numbers so that computers can understand. Chroma makes it easy to create embeddings from documents and find similar results with a few lines of code.
In the code below, the documents with IDs 1 and 2 closely match the given query text.
import chromadb
client = chromadb.Client()
collection = client.get_or_create_collection("test")
collection.add(
documents=[
"A man is eating food.",
"A man is eating yellow noodles.",
"The girl is carrying a baby.",
"A man is riding a horse.",
],
ids=["1", "2", "3", "4"],
)
query_result = collection.query(query_texts=["A man is eating pasta."], n_results=2)
print(query_result)
{'ids': [['2', '1']], 'distances': [[0.5690374970436096, 0.5929027199745178]], 'metadatas': [[{}, {}]], 'embeddings': None, 'documents': [['A man is eating yellow noodles.', 'A man is eating food.']]}
6.6.22. Galatic: Clean and Analyze Massive Text Datasets#
Show code cell content
!pip install galactic-ai
To clean, gain insights, and create embeddings from massive unstructured text datasets, use Galatic.
from galactic import GalacticDataset
filter_func = lambda x: len(x["content"]) < 1024
dataset = GalacticDataset.from_hugging_face_stream(
"tiiuae/falcon-refinedweb",
split="train",
filters=[filter_func],
dedup_fields=["content"],
max_samples=5000,
)
## Detect the language of the text
from collections import Counter
dataset.detect_language(field="content")
Counter(dataset["__language"])
Counter({'en': 4975,
'es': 7,
'fr': 7,
'de': 3,
'da': 2,
'ru': 1,
'nl': 1,
'pt': 1,
'sh': 1,
'eo': 1,
'ceb': 1})
## Get personal information from the text
dataset.detect_pii(fields=["content"])
print("Email:", sum(dataset["__pii__email"]))
print("Phone:", sum(dataset["__pii__phone"]))
print("Username/Password:", sum(dataset["__pii__credential"]))
Map: 100%|██████████| 5000/5000 [00:03<00:00, 1443.36 examples/s]
INFO: Detected PII in fields: ['content']; added __pii__email, __pii__phone, __pii__credential, and __pii__any metadata.
Email: 285
Phone: 242
Username/Password: 9
## Filter out all examples that have "blogspot" in the URL.
dataset = dataset.filter_string(fields=["url"], values=["blogspot"])
Filter: 100%|██████████| 5000/5000 [00:00<00:00, 107937.60 examples/s]
INFO: Filtered dataset in-place with exact string matching on fields: ['url']
# Create embeddings
dataset.get_embeddings(input_field="content", backend="cpu")
## Cluster the embeddings with kmeans
dataset.cluster(n_clusters=5, overwrite=True)
dataset.get_cluster_info()
WARNING: You already have clusters in field __cluster. Since overwrite=True, these will be overwritten.
INFO: Embedding dimension is large, which is fine! But consider also experimenting with dimensionality reduction before clustering.
Map: 100%|██████████| 4902/4902 [00:00<00:00, 31476.11 examples/s]
Cluster 1 (1095 items)
Cluster 4 (1125 items)
Cluster 0 (709 items)
Cluster 3 (1224 items)
Cluster 2 (749 items)
[{'cluster_id': 1, 'cluster_size': 1095, 'examples': [{}, {}, {}]},
{'cluster_id': 4, 'cluster_size': 1125, 'examples': [{}, {}, {}]},
{'cluster_id': 0, 'cluster_size': 709, 'examples': [{}, {}, {}]},
{'cluster_id': 3, 'cluster_size': 1224, 'examples': [{}, {}, {}]},
{'cluster_id': 2, 'cluster_size': 749, 'examples': [{}, {}, {}]}]
6.6.23. Efficient Keyword Extraction and Replacement with FlashText#
Show code cell content
!pip install flashtext
If you want to perform fast keyword extraction and replacement in text, use FlashText.
from flashtext import KeywordProcessor
keyword_processor = KeywordProcessor()
## Adding keywords with replacements
keyword_processor.add_keyword(keyword="Python")
keyword_processor.add_keyword(keyword="DS", clean_name="data science")
## Replacing keywords in text
new_sentence = keyword_processor.replace_keywords("PYTHON is essential for DS.")
new_sentence
'Python is essential for data science.'
6.6.24. BERTopic: Harnessing BERT for Interpretable Topic Modeling#
Show code cell content
!pip install bertopic
Managing and understanding large collections of text documents results in complex workflows with multiple preprocessing steps and difficult-to-interpret results. This causes data scientists to spend significant time trying to make sense of their document clusters and explaining them to stakeholders.
With BERTopic, you can leverage state-of-the-art language models to create more meaningful and interpretable topics. You get automatic topic labeling, visualization capabilities, and the flexibility to customize the modeling process according to your needs.
For this example, we use the popular 20 Newsgroups dataset which contains roughly 18000 newsgroups posts
from sklearn.datasets import fetch_20newsgroups
docs = fetch_20newsgroups(subset="all", remove=("headers", "footers", "quotes"))["data"]
In this example, we will go through the main components of BERTopic and the steps necessary to create a strong topic model.
We start by instantiating BERTopic. We set language to english since our documents are in the English language.
from bertopic import BERTopic
topic_model = BERTopic(language="english", verbose=True)
topics, probs = topic_model.fit_transform(docs)
After fitting our model, we can start by looking at the results. Typically, we look at the most frequent topics first as they best represent the collection of documents.
freq = topic_model.get_topic_info()
freq.head(5)
| Topic | Count | Name | Representation | Representative_Docs | |
|---|---|---|---|---|---|
| 0 | -1 | 6789 | -1_to_the_is_of | [to, the, is, of, and, you, for, it, in, that] | [It's like refusing 'God's kingdom come'.\n\nI... |
| 1 | 0 | 1823 | 0_game_team_games_he | [game, team, games, he, players, season, hocke... | [\n\n"Deeply rooted rivalry?" Ahem, Jokerit ha... |
| 2 | 1 | 630 | 1_key_clipper_chip_encryption | [key, clipper, chip, encryption, keys, escrow,... | [\nI am not an expert in the cryptography scie... |
| 3 | 2 | 527 | 2_idjits_ites_cheek_dancing | [idjits, ites, cheek, dancing, yep, consistent... | [consistently\n\n\n, \nYep.\n, \nDancing With ... |
| 4 | 3 | 446 | 3_israel_israeli_jews_arab | [israel, israeli, jews, arab, arabs, jewish, p... | [\nThis a "tried and true" method utilized by ... |
-1 refers to all outliers and should typically be ignored. Next, let’s take a look at a frequent topic that were generated:
topic_model.get_topic(0) # Select the most frequent topic
[('game', 0.010318688564543007),
('team', 0.008992489388365084),
('games', 0.0071658097402482355),
('he', 0.006986923839656088),
('players', 0.00631255726099582),
('season', 0.006207025740053),
('hockey', 0.006108581738112714),
('play', 0.0057638598847672895),
('25', 0.005625421684874428),
('year', 0.005577343029862753)]
Access the predicted topics for the first 10 documents:
topic_model.topics_[:10]
[0, -1, 54, 29, 92, -1, -1, 0, 0, -1]
Visualize topics:
topic_model.visualize_topics()
We can visualize the selected terms for a few topics by creating bar charts out of the c-TF-IDF scores for each topic representation. Insights can be gained from the relative c-TF-IDF scores between and within topics. Moreover, you can easily compare topic representations to each other.
fig = topic_model.visualize_barchart(top_n_topics=8)
fig.show()
6.6.25. BertTopic: Enhance Topic Models with Expert-Defined Themes#
!pip install -U bertopic
Data scientists and analysts often need to guide their topic modeling process with domain knowledge or specific themes they want to extract, but traditional topic modeling approaches don’t allow for this kind of control over the generated topics.
BERTopic is a topic modeling library that leverages BERT embeddings and c-TF-IDF to create easily interpretable topics.
Seed words are predefined sets of words that represent themes or topics you expect or want to find in your documents. BERTopic allows you to guide the topic modeling process using these seed words. By providing seed words, you can:
Direct the model towards specific themes of interest
Incorporate domain expertise into the topic discovery process
Ensure certain important themes are captured
Here’s how to implement guided topic modeling with seed words:
from bertopic import BERTopic
from sklearn.datasets import fetch_20newsgroups
## Load example data
docs = fetch_20newsgroups(subset="all", remove=("headers", "footers", "quotes"))["data"]
## Define seed topics
seed_topic_list = [
["drug", "cancer", "drugs", "doctor"],
["windows", "drive", "dos", "file"],
["space", "launch", "orbit", "lunar"],
]
# Create and train the model with seed topics
topic_model = BERTopic(seed_topic_list=seed_topic_list)
topics, probs = topic_model.fit_transform(docs)
## Look at three different topics in detail
print("\nFirst topic (Sports):")
print(topic_model.get_topic(0))
print("\nSecond topic (Cryptography):")
print(topic_model.get_topic(1))
print("\nFifth topic (Space Exploration):")
print(topic_model.get_topic(4))
First topic (Sports):
[('game', 0.010652628093406865), ('team', 0.00926068750809855), ('games', 0.007348381606302089), ('he', 0.007269166754797321), ('players', 0.0064590662792896585), ('season', 0.006363054536286731), ('hockey', 0.0062471104261567646), ('play', 0.00588900633935797), ('25', 0.0058020704180533665), ('year', 0.0057704732354528256)]
Second topic (Cryptography):
[('key', 0.015048608360916427), ('clipper', 0.01296513058488493), ('chip', 0.012280939589777724), ('encryption', 0.0113360913460819), ('keys', 0.010264402444887343), ('escrow', 0.00879797125029002), ('government', 0.007993957748991226), ('nsa', 0.007754136375078246), ('algorithm', 0.0071321814454188845), ('be', 0.006736358725450975)]
Fifth topic (Space Exploration):
[('space', 0.019632186075287533), ('launch', 0.01637819364726209), ('orbit', 0.010814499200447799), ('lunar', 0.01073417039148073), ('moon', 0.008701297355282599), ('nasa', 0.007899578915680364), ('shuttle', 0.006732791659778612), ('mission', 0.006472264420227003), ('earth', 0.006001769831975551), ('station', 0.005720802001625725)]
The results show how seed words influence topic discovery:
Seed Word Integration: In Topic 5, space-related seed words (‘space’, ‘launch’, ‘orbit’, ‘lunar’) have high weights. The model expands on these words to include related terms like ‘shuttle’, ‘mission’, and ‘station’.
Natural Topic Discovery: The model discovers prominent topics like sports (Topic 0) and cryptography (Topic 1), despite being seeded with medical and computer themes. This shows that seed words guide the model without constraining it.
6.6.26. BertViz: Visualize NLP Model Attention Patterns#
Show code cell content
!pip install bertviz
Understanding how attention mechanisms work in transformer models is challenging due to the complex interactions between multiple attention heads across different layers.
BertViz allows you to interactively visualize and explore attention patterns through multiple views.
from transformers import AutoModel, AutoTokenizer, utils
utils.logging.set_verbosity_error() # Suppress standard warnings
## Find popular HuggingFace models here: https://huggingface.co/models
model_name = "microsoft/xtremedistil-l12-h384-uncased"
input_text = "The cat sat on the mat"
## Configure model to return attention values
model = AutoModel.from_pretrained(model_name, output_attentions=True)
tokenizer = AutoTokenizer.from_pretrained(model_name)
## Tokenize input text
inputs = tokenizer.encode(input_text, return_tensors="pt")
## Run model
outputs = model(inputs)
## Retrieve attention from model outputs
attention = outputs[-1]
## Convert input ids to token strings
tokens = tokenizer.convert_ids_to_tokens(inputs[0])
from bertviz import head_view, model_view
## Display model view
model_view(attention, tokens)
## Display head view
head_view(attention, tokens)
6.6.27. Beyond Keywords: Building a Semantic Recipe Search Engine#
Semantic search enables content discovery based on meaning rather than just keywords. This approach uses vector embeddings - numerical representations of text that capture semantic essence.
By converting text to vector embeddings, we can quantify semantic similarity between different pieces of content in a high-dimensional vector space. This allows for comparison and search based on underlying meaning, surpassing simple keyword matching.
Here’s a Python implementation of semantic search for recipe recommendations using sentence-transformers:
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
## Step 1: Prepare our data
recipes = [
"Banana and Date Sweetened Oatmeal Cookies",
"No-Bake Berry Chia Seed Pudding",
"Deep-Fried Oreo Sundae with Caramel Sauce",
"Loaded Bacon Cheeseburger Pizza",
]
## Step 2: Load a pre-trained model for creating embeddings
model = SentenceTransformer("all-MiniLM-L6-v2")
## Step 3: Create embeddings for our recipe descriptions
recipe_embeddings = model.encode(recipes)
## Step 4: Function to find similar recipes
def find_similar_recipes(query, top_k=2):
# Create embedding for the query
query_embedding = model.encode([query])
# Calculate similarity
similarities = cosine_similarity(query_embedding, recipe_embeddings)[0]
# Get top k similar recipes
top_indices = similarities.argsort()[-top_k:][::-1]
return [(recipes[i], similarities[i]) for i in top_indices]
## Step 5: Test our semantic search
query = "healthy dessert without sugar"
results = find_similar_recipes(query)
print(f"Query: {query}")
print("Most similar recipes:")
for recipe, score in results:
print(f"- {recipe} (Similarity: {score:.2f})")
Query: healthy dessert without sugar
Most similar recipes:
- No-Bake Berry Chia Seed Pudding (Similarity: 0.55)
- Banana and Date Sweetened Oatmeal Cookies (Similarity: 0.43)
6.6.28. SkillNER: Automating Skill Extraction in Python#
Show code cell content
!pip install skillNer
Show code cell content
!python -m spacy download en_core_web_lg
Extracting skills from job postings, resumes, or other unstructured text can be time-consuming if done manually. SkillNER automates this process, making it faster and more efficient.
This tool can be useful for:
Recruiters to automate skill extraction for faster candidate screening.
Data scientists to extract structured data from unstructured job-related text.
Here’s a quick example:
import spacy
from skillNer.general_params import SKILL_DB
from skillNer.skill_extractor_class import SkillExtractor
from spacy.matcher import PhraseMatcher
## Load the spaCy model
nlp = spacy.load("en_core_web_lg")
## Initialize the SkillExtractor
skill_extractor = SkillExtractor(nlp, SKILL_DB, PhraseMatcher)
## Sample job description
job_description = """
You are a data scientist with strong expertise in Python. You have solid experience in
data analysis and visualization, and can manage end-to-end data science projects.
You quickly adapt to new tools and technologies, and are fluent in both English and SQL.
"""
## Extract skills from the job description
annotations = skill_extractor.annotate(job_description)
annotations
{'text': 'you are a data scientist with strong expertise in python you have solid experience in data analysis and visualization and can manage end to end data science projects you quickly adapt to new tools and technologies and are fluent in both english and sql',
'results': {'full_matches': [{'skill_id': 'KS120GV6C72JMSZKMTD7',
'doc_node_value': 'data analysis',
'score': 1,
'doc_node_id': [15, 16]}],
'ngram_scored': [{'skill_id': 'KS125LS6N7WP4S6SFTCK',
'doc_node_id': [9],
'doc_node_value': 'python',
'type': 'fullUni',
'score': 1,
'len': 1},
{'skill_id': 'KS1282T6STD9RJZ677XL',
'doc_node_id': [18],
'doc_node_value': 'visualization',
'type': 'fullUni',
'score': 1,
'len': 1},
{'skill_id': 'KS1218W78FGVPVP2KXPX',
'doc_node_id': [21],
'doc_node_value': 'manage',
'type': 'lowSurf',
'score': 0.63417345,
'len': 1},
{'skill_id': 'KS7LO8P3MXB93R3C9RWL',
'doc_node_id': [25, 26],
'doc_node_value': 'data science',
'type': 'lowSurf',
'score': 2,
'len': 2},
{'skill_id': 'KS120626HMWCXJWJC7VK',
'doc_node_id': [30],
'doc_node_value': 'adapt',
'type': 'lowSurf',
'score': 0.503605,
'len': 1},
{'skill_id': 'KS123K75YYK8VGH90NCS',
'doc_node_id': [41],
'doc_node_value': 'english',
'type': 'lowSurf',
'score': 1,
'len': 1},
{'skill_id': 'KS440W865GC4VRBW6LJP',
'doc_node_id': [43],
'doc_node_value': 'sql',
'type': 'fullUni',
'score': 1,
'len': 1}]}}
skill_extractor.describe(annotations)
6.6.29. nlpaug: Enhancing NLP Model Performance with Data Augmentation#
Show code cell content
!pip install nlpaug
Limited training data for natural language processing tasks often results in overfitting and poor generalization of models.
The nlpaug library offers diverse NLP data augmentation techniques, helping researchers expand datasets and create robust models.
import nlpaug.augmenter.char as nac
import nlpaug.augmenter.sentence as nas
import nlpaug.augmenter.word as naw
Substitute character by keyboard distance:
text = "The quick brown fox jumps over the lazy dog."
aug = nac.KeyboardAug()
augmented_text = aug.augment(text)
print("Original:")
print(text)
print("Augmented Text:")
print(augmented_text)
Original:
The quick brown fox jumps over the lazy dog.
Augmented Text:
['The quUci b%oan fox j tJps over the lazy dog.']
Insert character randomly:
aug = nac.RandomCharAug(action="insert")
augmented_text = aug.augment(text)
print("Original:")
print(text)
print("Augmented Text:")
print(augmented_text)
Original:
The quick brown fox jumps over the lazy dog.
Augmented Text:
['The quick Hbr2own fox jumps Govner the slahzy dog.']
Substitute word by spelling mistake words dictionary:
aug = naw.SpellingAug()
augmented_texts = aug.augment(text, n=3)
print("Original:")
print(text)
print("Augmented Texts:")
print(augmented_texts)
Original:
The quick brown fox jumps over the lazy dog.
Augmented Texts:
['Then quikly brown fox jumps over the lazy dig.', 'Th quikly brown fox jumps over the lazy doy.', 'The quick brouwn fox jumps over the lizy doga.']
Insert word by contextual word embeddings (BERT, DistilBERT, RoBERTA or XLNet):
aug = naw.ContextualWordEmbsAug(model_path="bert-base-uncased", action="substitute")
augmented_text = aug.augment(text)
print("Original:")
print(text)
print("Augmented Text:")
print(augmented_text)
Original:
The quick brown fox jumps over the lazy dog.
Augmented Text:
['the wild brown fox was over the big dog.']
Substitute word by WordNet’s synonym:
aug = naw.SynonymAug(aug_src="wordnet")
augmented_text = aug.augment(text)
print("Original:")
print(text)
print("Augmented Text:")
print(augmented_text)
Original:
The quick brown fox jumps over the lazy dog.
Augmented Text:
['The ready brown slyboots jumps over the indolent dog.']
Split word to two tokens randomly:
aug = naw.SplitAug()
augmented_text = aug.augment(text)
print("Original:")
print(text)
print("Augmented Text:")
print(augmented_text)
Original:
The quick brown fox jumps over the lazy dog.
Augmented Text:
['The qui ck br own fox jumps o ver the lazy dog.']
6.6.30. GLiNER: The Lightweight Alternative to LLMs for Custom NER#
Show code cell content
!pip install gliner spacy
Show code cell content
!python -m spacy download en_core_web_sm
Traditional NER models are limited to predefined entity types. For example, spaCy’s default English model is trained to recognize only the follwoing entity types:
PERSON (e.g., “John Smith”)
ORG (e.g., “Microsoft”)
GPE (e.g., “New York”)
DATE (e.g., “June 15th”)
MONEY (e.g., “$500”)
Example of a traditional approach with spaCy:
import spacy
## Load a pre-trained model with fixed entity types
nlp = spacy.load("en_core_web_sm")
text = """
Maria Rodriguez loves making sushi and pizza in her spare time. She practices yoga
and rock climbing on weekends in Boulder, Colorado. Her friend Tom enjoys baking
fresh croissants and often brings them when they go hiking together in the Rocky Mountains.
"""
## Can only detect pre-defined entity types
doc = nlp(text)
for ent in doc.ents:
print(f"{ent.text} => {ent.label_}")
Maria Rodriguez => PERSON
Boulder => GPE
Colorado => GPE
Tom => PERSON
the Rocky Mountains => LOC
Identifying and extracting other types of entities from text requires either training separate models for each entity type or using large language models, which results in high computational costs and resource requirements.
GLiNER allows you to extract any custom entity types from text using a lightweight model. You can specify the entity types you want to extract at inference time without retraining the model.
from gliner import GLiNER
## Initialize the model
model = GLiNER.from_pretrained("urchade/gliner_medium-v2.1")
text = """
Maria Rodriguez loves making sushi and pizza in her spare time. She practices yoga
and rock climbing on weekends in Boulder, Colorado. Her friend Tom enjoys baking
fresh croissants and often brings them when they go hiking together in the Rocky Mountains.
"""
## Define custom entity types
labels = ["Person", "Food", "Hobby", "Location"]
## Extract entities
entities = model.predict_entities(text, labels)
## Print the extracted entities
for entity in entities:
print(f"{entity['text']} => {entity['label']}")
/Users/khuyentran/book/venv/lib/python3.11/site-packages/transformers/convert_slow_tokenizer.py:561: UserWarning: The sentencepiece tokenizer that you are converting to a fast tokenizer uses the byte fallback option which is not implemented in the fast tokenizers. In practice this means that the fast version of the tokenizer can produce unknown tokens whereas the sentencepiece version would have converted these unknown tokens into a sequence of byte tokens matching the original piece of text.
warnings.warn(
Asking to truncate to max_length but no maximum length is provided and the model has no predefined maximum length. Default to no truncation.
Maria Rodriguez => Person
sushi => Food
pizza => Food
yoga => Hobby
rock climbing => Hobby
Boulder, Colorado => Location
Tom => Person
fresh croissants => Food
Rocky Mountains => Location
This example shows how GLiNER can identify multiple custom entity types (persons, foods, hobbies, and locations) in a single pass without needing separate models or extensive training for each category.