6.3. Get Data#
This section covers tools to get some data for your projects.
6.3.1. faker: Create Fake Data in One Line of Code#
Show code cell content
!pip install Faker
For quickly generating fake data for testing, use Faker.
Here are a few examples:
from faker import Faker
fake = Faker()
fake.color_name()
'CornflowerBlue'
fake.name()
'Michael Scott'
fake.address()
'881 Patricia Crossing\nSouth Jeremy, AR 06087'
fake.date_of_birth(minimum_age=22)
datetime.date(1927, 11, 5)
fake.city()
'North Donald'
fake.job()
'Teacher, secondary school'
6.3.2. Silly: Produce Silly Test Data#
Show code cell content
!pip install silly
For generating playful test data, try the silly library.
Here are some examples:
import silly
name = silly.name()
email = silly.email()
print(f"Her name is {name}. Her email is {email}")
Her name is olivia ringslap.Her email is boatbench@thirty-three-mighty-horses.link
silly.a_thing()
'five cherry onions'
silly.thing()
'container of khaki wads'
silly.things()
'a tote of plans, twenty-four eyes, and eighteen garlic arms'
silly.sentence()
"God himself can't wait to move a hat in Birmingpoop."
silly.paragraph()
"Agustin Neutral-Jerk needs a group of concerns, badly. Agnes Basil can't wait to taste a box of slate chairs in Assesford. To get to Testasia, you need to go to Fantasticheartsound, then drive east. The band 'Queen' will hurl a dance. To get to Arztotzka, you need to go to Cape City Central, then drive north. The world will head to Integrated Eye And Onion to buy a tub of boots. Assemble jean! Seth Violetbag will assemble a laudable ring. Lampton is in South Yemen. Birmingobject is in West Cybertron."
6.3.3. Random User: Generate Random User Data in One Line of Code#
Need to generate fake user data for testing? The Random User Generator API provides a simple way to get random user data. Here’s how you can fetch and use this data in your code:
import json
from urllib.request import urlopen
## Show 2 random users
data = urlopen("https://randomuser.me/api?results=2").read()
users = json.loads(data)["results"]
users
[{'gender': 'female',
'name': {'title': 'Miss', 'first': 'Ava', 'last': 'Hansen'},
'location': {'street': {'number': 3526, 'name': 'George Street'},
'city': 'Worcester',
'state': 'Merseyside',
'country': 'United Kingdom',
'postcode': 'K7Z 3WB',
'coordinates': {'latitude': '11.9627', 'longitude': '17.6871'},
'timezone': {'offset': '+9:00',
'description': 'Tokyo, Seoul, Osaka, Sapporo, Yakutsk'}},
'email': 'ava.hansen@example.com',
'login': {'uuid': '253e53f9-9553-4345-9047-fb18aec51cfe',
'username': 'heavywolf743',
'password': 'cristina',
'salt': 'xwnpqwtd',
'md5': '2b5037da7d78258f167d5a3f8dc24edb',
'sha1': 'fabbede0577b3fed686afd319d5ab794f1b35b02',
'sha256': 'd42e2061f9c283c4548af6c617727215c79ecafc74b9f3a294e6cf09afc5906f'},
'dob': {'date': '1948-01-21T10:26:00.053Z', 'age': 73},
'registered': {'date': '2011-11-19T03:28:46.830Z', 'age': 10},
'phone': '015242 07811',
'cell': '0700-326-155',
'id': {'name': 'NINO', 'value': 'HT 97 25 71 Y'},
'picture': {'large': 'https://randomuser.me/api/portraits/women/60.jpg',
'medium': 'https://randomuser.me/api/portraits/med/women/60.jpg',
'thumbnail': 'https://randomuser.me/api/portraits/thumb/women/60.jpg'},
'nat': 'GB'},
{'gender': 'male',
'name': {'title': 'Mr', 'first': 'Aubin', 'last': 'Martin'},
'location': {'street': {'number': 8496, 'name': "Rue du Bât-D'Argent"},
'city': 'Strasbourg',
'state': 'Meurthe-et-Moselle',
'country': 'France',
'postcode': 83374,
'coordinates': {'latitude': '-1.3192', 'longitude': '24.0062'},
'timezone': {'offset': '+10:00',
'description': 'Eastern Australia, Guam, Vladivostok'}},
'email': 'aubin.martin@example.com',
'login': {'uuid': '54b9bfa9-5e86-4335-8ae3-164d85df98e7',
'username': 'heavyladybug837',
'password': 'kendra',
'salt': 'LcEMyR5s',
'md5': '2fbd9e05d992eb74f7afcccec02581fc',
'sha1': '530a1bc71a986415176606ea377961d2ce381e5d',
'sha256': 'f5ee7bc47f5615e89f1729dcb49632c6b76a90ba50eb42d782e2790398ebc539'},
'dob': {'date': '1949-04-12T05:01:31.463Z', 'age': 72},
'registered': {'date': '2006-05-28T03:54:36.433Z', 'age': 15},
'phone': '01-88-32-00-30',
'cell': '06-09-79-55-81',
'id': {'name': 'INSEE', 'value': '1NNaN48231023 75'},
'picture': {'large': 'https://randomuser.me/api/portraits/men/65.jpg',
'medium': 'https://randomuser.me/api/portraits/med/men/65.jpg',
'thumbnail': 'https://randomuser.me/api/portraits/thumb/men/65.jpg'},
'nat': 'FR'}]
6.3.4. fetch_openml: Get OpenML’s Dataset in One Line of Code#
OpenML offers a variety of intriguing datasets. You can easily fetch these datasets in Python using sklearn.datasets.fetch_openml.
Here’s how to load an OpenML dataset with a single line of code:
from sklearn.datasets import fetch_openml
monk = fetch_openml(name="monks-problems-2", as_frame=True)
print(monk["data"].head(10))
attr1 attr2 attr3 attr4 attr5 attr6
0 1 1 1 1 2 2
1 1 1 1 1 4 1
2 1 1 1 2 1 1
3 1 1 1 2 1 2
4 1 1 1 2 2 1
5 1 1 1 2 3 1
6 1 1 1 2 4 1
7 1 1 1 3 2 1
8 1 1 1 3 4 1
9 1 1 2 1 1 1
6.3.5. Autoscraper: Automate Web Scraping in Python#
Show code cell content
!pip install autoscraper
To automate web scraping with minimal code, try autoscraper.
Here’s a quick example to extract specific elements from a webpage:
from autoscraper import AutoScraper
url = "https://stackoverflow.com/questions/2081586/web-scraping-with-python"
wanted_list = ["How to check version of python modules?"]
scraper = AutoScraper()
result = scraper.build(url, wanted_list)
for res in result:
print(res)
How to execute a program or call a system command?
What are metaclasses in Python?
Does Python have a ternary conditional operator?
Convert bytes to a string
Does Python have a string 'contains' substring method?
How to check version of python modules?
6.3.6. pandas-reader: Extract Data from Various Internet Sources Directly into a Pandas DataFrame#
Show code cell content
!pip install pandas-datareader
To retrieve time series data from various internet sources directly into a pandas DataFrame, use pandas-datareader.
Here’s how you can fetch daily data of the AD indicator from 2008 to 2018:
import os
from datetime import datetime
import pandas_datareader.data as web
df = web.DataReader(
"AD",
"av-daily",
start=datetime(2008, 1, 1),
end=datetime(2018, 2, 28),
api_key=os.gehide-outputtenv("ALPHAVANTAGE_API_KEY"),
)
6.3.7. pytrends: Get the Trend of a Keyword on Google Search Over Time#
Show code cell content
!pip install pytrends
To analyze keyword trends on Google Search, use pytrends.
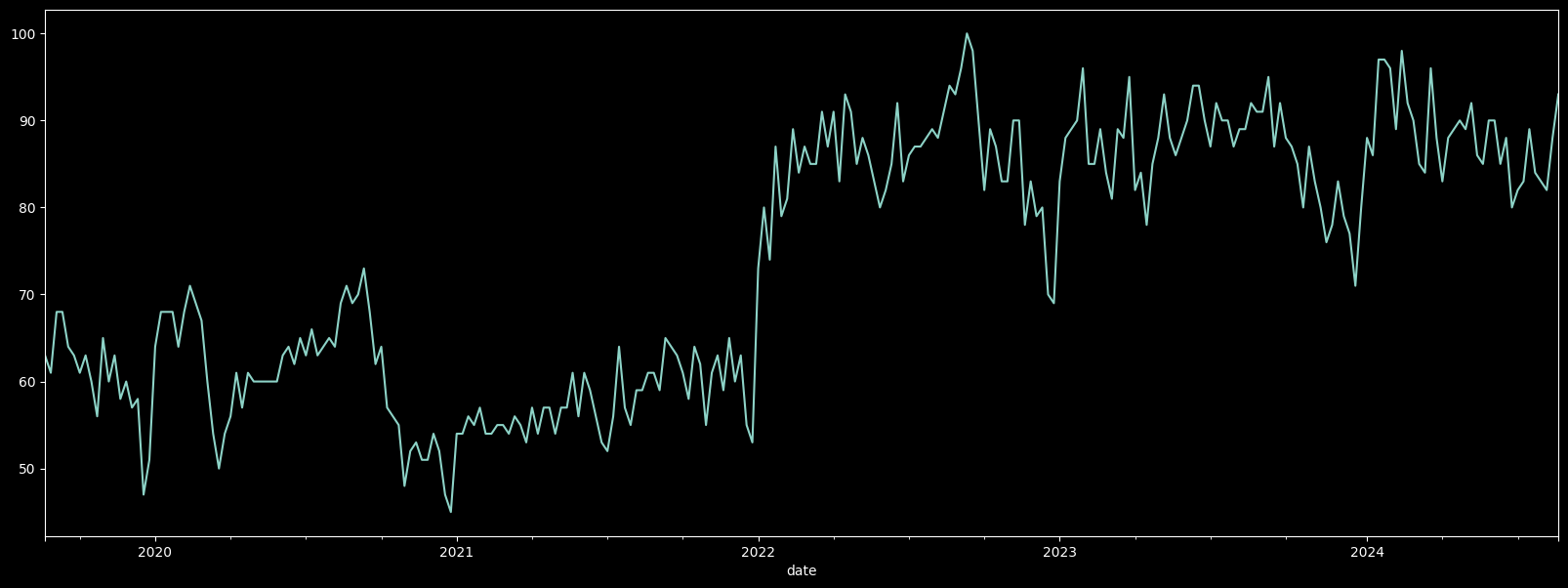
Here’s an example to track the trend of the keyword “data science” from 2019 to 2024:
from pytrends.request import TrendReq
pytrends = TrendReq(hl="en-US", tz=360)
pytrends.build_payload(kw_list=["data science"])
df = pytrends.interest_over_time()
df["data science"].plot(figsize=(20, 7))
/Users/khuyentran/book/venv/lib/python3.11/site-packages/pytrends/request.py:260: FutureWarning: Downcasting object dtype arrays on .fillna, .ffill, .bfill is deprecated and will change in a future version. Call result.infer_objects(copy=False) instead. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
df = df.fillna(False)
<Axes: xlabel='date'>
6.3.9. Datacommons: Get Statistics about a Location in One Line of Code#
Show code cell content
!pip install datacommons
To get statistics about a location with one line of code, use datacommons.
import datacommons_pandas
import plotly.express as px
import pandas as pd
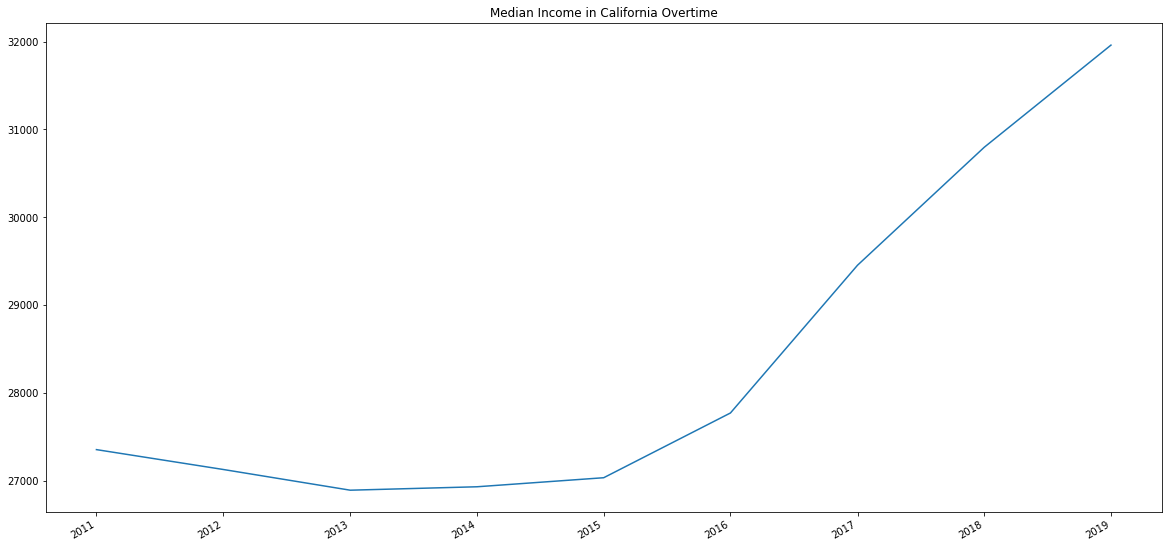
Here’s how to find median income in California over time:
median_income = datacommons_pandas.build_time_series("geoId/06", "Median_Income_Person")
median_income.index = pd.to_datetime(median_income.index)
median_income.plot(
figsize=(20, 10),
x="Income",
y="Year",
title="Median Income in California Over Time",
)
<AxesSubplot:title={'center':'Median Income in California Overtime'}>
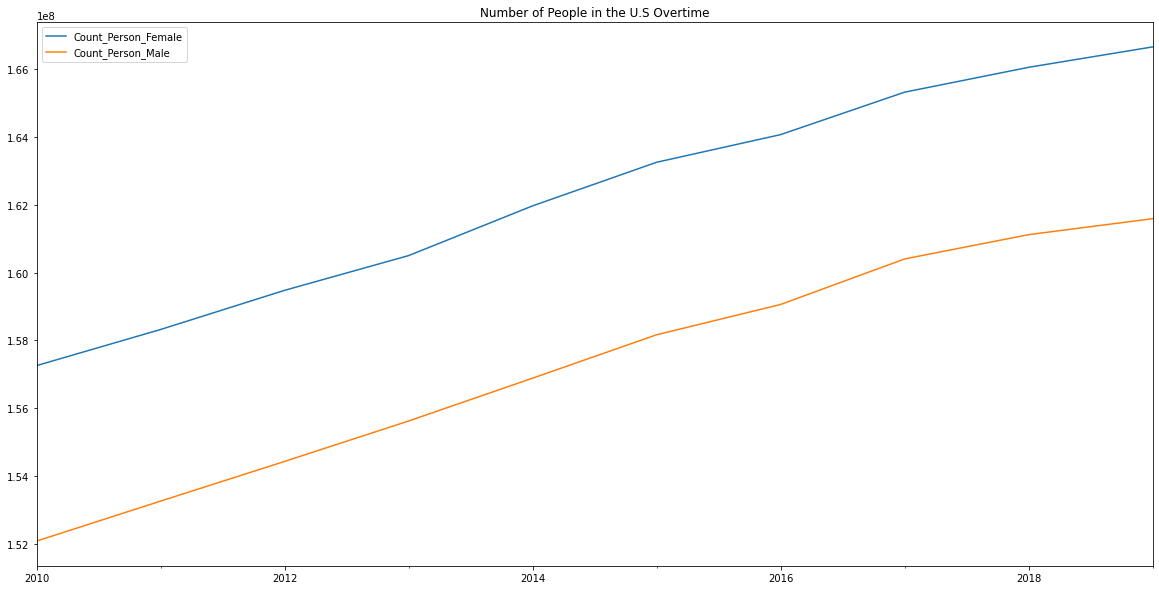
To visualize the number of people in the U.S. over time:
def process_ts(statistics: str):
count_person = datacommons_pandas.build_time_series('country/USA', statistics)
count_person.index = pd.to_datetime(count_person.index)
count_person.name = statistics
return count_person
count_person_male = process_ts('Count_Person_Male')
count_person_female = process_ts('Count_Person_Female')
count_person = pd.concat([count_person_female, count_person_male], axis=1)
count_person.plot(
figsize=(20, 10),
title="Number of People in the U.S Over Time",
)
<AxesSubplot:title={'center':'Number of People in the U.S Overtime'}>
6.3.10. Get Google News Using Python#
Show code cell content
!pip install GoogleNews
To retrieve Google News results for a specific keyword and date range, use the GoogleNews library.
Here’s how you can get news articles related to a keyword within a given time period:
from GoogleNews import GoogleNews
googlenews = GoogleNews()
googlenews.set_time_range('02/01/2022','03/25/2022')
googlenews.search('funny')
googlenews.results()
[{'title': 'Hagan has fastest NHRA Funny Car run in 4 years',
'media': 'ESPN',
'date': 'Feb 26, 2022',
'datetime': datetime.datetime(2022, 2, 26, 0, 0),
'desc': '-- Matt Hagan made the quickest Funny Car run in four years Saturday, \ngiving the new Tony Stewart Racing NHRA team its first No. 1 qualifier and \nsetting the...',
'link': 'https://www.espn.com/racing/story/_/id/33381149/matt-hagan-fastest-nhra-funny-car-pass-4-years',
'img': 'data:image/gif;base64,R0lGODlhAQABAIAAAP///////yH5BAEKAAEALAAAAAABAAEAAAICTAEAOw=='},
{'title': 'Full fields in Top Fuel, Funny Car, and Pro Stock promise fast ...',
'media': 'NHRA',
'date': 'Feb 10, 2022',
'datetime': datetime.datetime(2022, 2, 10, 0, 0),
'desc': 'The pits at Auto Club Raceway at Pomona will be packed with NHRA Camping \nWorld Drag Racing Series teams for the 2022 season-opening Lucas Oil NHRA...',
'link': 'https://www.nhra.com/news/2022/full-fields-top-fuel-funny-car-and-pro-stock-promise-fast-start-winternationals',
'img': 'data:image/gif;base64,R0lGODlhAQABAIAAAP///////yH5BAEKAAEALAAAAAABAAEAAAICTAEAOw=='},
{'title': 'Full Cast Set for Broadway Revival of Funny Girl, Starring ...',
'media': 'Playbill',
'date': 'Feb 7, 2022',
'datetime': datetime.datetime(2022, 2, 7, 0, 0),
'desc': 'Among those newly added to the company are Peter Francis James, Ephie \nAardema, Martin Moran, and Julie Benko. By Margaret Hall. February 07, 2022.',
'link': 'https://playbill.com/article/full-cast-set-for-broadway-revival-of-funny-girl-starring-beanie-feldstein-and-ramin-karimloo',
'img': 'data:image/gif;base64,R0lGODlhAQABAIAAAP///////yH5BAEKAAEALAAAAAABAAEAAAICTAEAOw=='},
{'title': 'Robert Hight tops Funny Car qualifying at season-opening Lucas Oil NHRA Winternationals',
'media': 'ESPN',
'date': 'Feb 18, 2022',
'datetime': datetime.datetime(2022, 2, 18, 0, 0),
'desc': "-- Robert Hight topped Funny Car qualifying Friday night in the NHRA \nCamping World Drag Racing Series' season-opening Lucas Oil NHRA \nWinternationals. Hight, a...",
'link': 'https://www.espn.com/racing/story/_/id/33324340/robert-hight-tops-funny-car-qualifying-season-opening-lucas-oil-nhra-winternationals',
'img': 'data:image/gif;base64,R0lGODlhAQABAIAAAP///////yH5BAEKAAEALAAAAAABAAEAAAICTAEAOw=='},
{'title': 'New NHRA Funny Car Team Owner Ron Capps Throws ...',
'media': 'Autoweek',
'date': 'Feb 21, 2022',
'datetime': datetime.datetime(2022, 2, 21, 0, 0),
'desc': 'Defending Funny Car champion enters season without automaker deal after \nlong-time partner turns him down. By Susan Wade. Feb 21, 2022.',
'link': 'https://www.autoweek.com/racing/nhra/a39160639/ron-capps-throws-dodgemopar-under-bus/',
'img': 'data:image/gif;base64,R0lGODlhAQABAIAAAP///////yH5BAEKAAEALAAAAAABAAEAAAICTAEAOw=='},
{'title': 'VIDEO: Beanie Feldstein, Ramin Karimloo, and More in ...',
'media': 'Broadway World',
'date': 'ar 9, 2022',
'datetime': None,
'desc': 'The highly anticipated Broadway revival of Funny Girl is beginning \nperformances this month! The musical will have its first preview at the \nAugust Wilson on...',
'link': 'https://www.broadwayworld.com/article/VIDEO-Beanie-Feldstein-Ramin-Karimloo-and-More-in-Rehearsal-For-FUNNY-GIRL-20220309',
'img': 'data:image/gif;base64,R0lGODlhAQABAIAAAP///////yH5BAEKAAEALAAAAAABAAEAAAICTAEAOw=='},
{'title': 'Watch: The Funny Girl Sitzprobe, With Beanie Feldstein and ...',
'media': 'TheaterMania',
'date': 'ar 24, 2022',
'datetime': None,
'desc': "Funny Girl is headed back to Broadway. Here is a first look at the cast's \nfirst orchestra rehearsal, with snippets of stars Beanie Feldstein, Ramin \nKarimloo...",
'link': 'https://www.theatermania.com/broadway/news/first-look-the-funny-girl-sitzprobe-with-beanie-fe_93550.html',
'img': 'data:image/gif;base64,R0lGODlhAQABAIAAAP///////yH5BAEKAAEALAAAAAABAAEAAAICTAEAOw=='},
{'title': 'Stephen Colbert, Funny or Die Prep Primetime Pickleball Special for CBS',
'media': 'The Hollywood Reporter',
'date': 'ar 15, 2022',
'datetime': None,
'desc': 'Stephen Colbert, Funny or Die Prep Primetime Pickleball Special for CBS. \nThe special, \'Pickled,\' will see celebrity competitors vie for the "Golden \nGherkin.".',
'link': 'https://www.hollywoodreporter.com/tv/tv-news/stephen-colbert-funny-or-die-primetime-pickleball-cbs-1235111617/',
'img': 'data:image/gif;base64,R0lGODlhAQABAIAAAP///////yH5BAEKAAEALAAAAAABAAEAAAICTAEAOw=='},
{'title': 'Randy Meyer Racing to debut injected nitro Funny Car at ...',
'media': 'NHRA',
'date': 'ar 22, 2022',
'datetime': None,
'desc': "The Funny Car Chaos deal is becoming more popular here in the Midwest, so \nit's an opportunity for us to go race close to home, have some fun, and \ntake on a new...",
'link': 'https://www.nhra.com/news/2022/randy-meyer-racing-debut-injected-nitro-funny-car-funny-car-chaos-event',
'img': 'data:image/gif;base64,R0lGODlhAQABAIAAAP///////yH5BAEKAAEALAAAAAABAAEAAAICTAEAOw=='},
{'title': 'Laurie Zaleski talks about her book “Funny Farm”',
'media': 'The Washington Post',
'date': 'Feb 25, 2022',
'datetime': datetime.datetime(2022, 2, 25, 0, 0),
'desc': "This is the Funny Farm, double-entendre intended: “Because it's full of \nanimals, and fit for lunatics,” Zaleski jokes of the sanctuary that she \nbuilt here,...",
'link': 'https://www.washingtonpost.com/books/2022/02/25/funny-farm-rescue-animals/',
'img': 'data:image/gif;base64,R0lGODlhAQABAIAAAP///////yH5BAEKAAEALAAAAAABAAEAAAICTAEAOw=='}]
6.3.11. people_also_ask: Python Wrapper for Google People Also Ask#
Show code cell content
!pip install people_also_ask
To interact with Google’s “People Also Ask” feature programmatically, use the people_also_ask library.
Here’s how to retrieve related questions and answers:
import people_also_ask as ask
ask.get_related_questions('data science')
['What exactly data science do?',
'Is data science a good career?',
'What are the 3 main concepts of data science?',
'Is data science a easy career?']
ask.get_answer('Is data science a easy career?')
{'has_answer': True,
'question': 'Is data science a easy career?',
'related_questions': ['Is becoming a data scientist easy?',
'Is data science a stressful career?',
'Is Python for data science hard?',
'Do data scientists code a lot?'],
'response': 'The short answer to the above question is a big NO! Data Science is hard to learn is primarily a misconception that beginners have during their initial days. As they discover the unique domain of data science more, they realise that data science is just another field of study that can be learned by working hard.Oct 4, 2022',
'heading': 'The short answer to the above question is a big NO! Data Science is hard to learn is primarily a misconception that beginners have during their initial days. As they discover the unique domain of data science more, they realise that data science is just another field of study that can be learned by working hard.Oct 4, 2022',
'title': 'Is Data Science Hard to Learn? (Answer: NO!) - ProjectPro',
'link': 'https://www.projectpro.io/article/is-data-science-hard-to-learn/522#:~:text=The%20short%20answer%20to%20the,be%20learned%20by%20working%20hard.',
'displayed_link': 'https://www.projectpro.io › article › is-data-science-hard-t...',
'snippet_str': 'The short answer to the above question is a big NO! Data Science is hard to learn is primarily a misconception that beginners have during their initial days. As they discover the unique domain of data science more, they realise that data science is just another field of study that can be learned by working hard.Oct 4, 2022\nhttps://www.projectpro.io › article › is-data-science-hard-t...\nhttps://www.projectpro.io/article/is-data-science-hard-to-learn/522#:~:text=The%20short%20answer%20to%20the,be%20learned%20by%20working%20hard.\nIs Data Science Hard to Learn? (Answer: NO!) - ProjectPro',
'snippet_data': None,
'date': None,
'snippet_type': 'Definition Featured Snippet',
'snippet_str_body': '',
'raw_text': 'Featured snippet from the web\nThe short answer to the above question is a big NO! \nData Science is hard to learn\n is primarily a misconception that beginners have during their initial days. As they discover the unique domain of data science more, they realise that data science is just another field of study that can be learned by working hard.\nOct 4, 2022\nIs Data Science Hard to Learn? (Answer: NO!) - ProjectPro\nhttps://www.projectpro.io\n › article › is-data-science-hard-t...'}
6.3.12. Scrape Facebook Public Pages Without an API Key#
Show code cell content
pip install facebook-scraper
To scrape Facebook public pages without needing an API key, use the facebook-scraper library.
You can use facebook-scraper to extract information from public profiles and groups. Here’s how you can do it:
Get group information:
from facebook_scraper import get_profile, get_group_info
get_group_info("thedachshundowners")
{'id': '2685753618191566',
'name': 'Dachshund Owners',
'type': 'Public group',
'members': 128635,
'about': "Hello, Welcome to the Dachshund Owners group.\nPost pictures/videos, share stories, ask advise from other Dachshund lovers.\nYou can post YOUR videos / pics of your Dachshund if they’ve got that viral element, your dog will be seen by millions of people around the globe.\n\n* RULES AND POSTING GUIDELINES\n✅ Post original contents that you created ONLY\n✅ Post with a short description/story about the content\n✅ Include if you want to be credited or not\n✅ Be nice to other members\n❌ No aggressive behavior\n❌ No backyard breeding\n❌ No spam\n❌ No unrelated content or video\n\n🐾 Selling dogs are PROHIBITED. Any transactions made with our group from this point forward will be at your own risk.\n🐾No Promotions - include(s) SELLING/PROMOTING ITEM(s) Fishing potential buyers. We are just protecting each and everyone from scams!\n\n🛍️ Hello, Sir or Lady.\nThe Dachshund Owners group administrator is speaking.\nWe appreciate you being here. We want to let you know that managing spam and other related tasks is difficult with so many posts to approve. It's a very time-consuming task, and that's why we need your support. Please buy a T-shirt from us so we can keep the group running and providing awesome value! You can get a T-shirt, mug, Canvas, and other items from us that can be customized for Dog lovers. On our Store, you may check out our customized campaigns. Thank You! 😊\n🛒 Store Link: https://www.pawowners.com/collectio..."}
Get profile information
get_profile("zuck")
{'Friend_count': None,
'Follower_count': None,
'Following_count': None,
'cover_photo': 'https://scontent-ord5-1.xx.fbcdn.net/v/t31.18172-8/19575079_10103832396388711_8894816584589808440_o.jpg?stp=cp0_dst-jpg_e15_fr_q65&_nc_cat=1&ccb=1-7&_nc_sid=ed5ff1&_nc_ohc=Z5jCEAhNv3AAX9ihcdv&_nc_ht=scontent-ord5-1.xx&oh=00_AfCTBrP26zWK0onpRfKbpJLRlFDwWLmlv1_XlkeVLkE_yw&oe=63CA953D',
'profile_picture': 'https://scontent-ord5-1.xx.fbcdn.net/v/t39.30808-1/312257846_10114737758665291_6588360857015169674_n.jpg?stp=cp0_dst-jpg_e15_q65_s120x120&_nc_cat=1&ccb=1-7&_nc_sid=dbb9e7&_nc_ohc=x2_MUzaxC2cAX9w6LZ6&_nc_ht=scontent-ord5-1.xx&oh=00_AfDiKcBBDdzCymHXd-yjp2stit_VGPQRm9oeibSyDFG8BA&oe=63A81F9E',
'id': '4',
'Name': 'Mark Zuckerberg',
'Work': 'Chan Zuckerberg Initiative\nDecember 1, 2015 - Present\nMeta\nFounder and CEO\nFebruary 4, 2004 - Present\nPalo Alto, California\nBringing the world closer together.',
'Education': 'Harvard University\nComputer Science and Psychology\nAugust 30, 2002 - April 30, 2004\nPhillips Exeter Academy\nClassics\nClass of 2002\nArdsley High School\nHigh school\nAugust 1998 - May 2000',
'Places lived': [{'link': '/profile.php?id=104022926303756&refid=17',
'text': 'Palo Alto, California',
'type': 'Current city'},
{'link': '/profile.php?id=105506396148790&refid=17',
'text': 'Dobbs Ferry, New York',
'type': 'Hometown'}],
'About': "I'm trying to make the world a more open place.",
'Favorite quotes': '"Fortune favors the bold."\n- Virgil, Aeneid X.284\n\n"All children are artists. The problem is how to remain an artist once you grow up."\n- Pablo Picasso\n\n"Make things as simple as possible but no simpler."\n- Albert Einstein'}
6.3.13. Recipe-Scrapers: Automate Recipe Data Extraction#
Show code cell content
!pip install recipe-scrapers
For automated recipe data extraction, use the recipe-scrapers library. It simplifies the process of gathering recipe information from various websites.
from recipe_scrapers import scrape_me
scraper = scrape_me('https://cookieandkate.com/thai-red-curry-recipe/')
scraper.host()
'cookieandkate.com'
scraper.title()
'Thai Red Curry with Vegetables'
scraper.total_time()
40
scraper.ingredients()
['1 ¼ cups brown jasmine rice or long-grain brown rice, rinsed',
'1 tablespoon coconut oil or olive oil',
'1 small white onion, chopped (about 1 cup)',
'Pinch of salt, more to taste',
'1 tablespoon finely grated fresh ginger (about a 1-inch nub of ginger)',
'2 cloves garlic, pressed or minced',
'1 red bell pepper, sliced into thin 2-inch long strips',
'1 yellow, orange or green bell pepper, sliced into thin 2-inch long strips',
'3 carrots, peeled and sliced on the diagonal into ¼-inch thick rounds (about 1 cup)',
'2 tablespoons Thai red curry paste*',
'1 can (14 ounces) regular coconut milk**',
'1/2 cup water',
'1 1/2 cups packed thinly sliced kale (tough ribs removed first), preferably the Tuscan/lacinato/dinosaur variety',
'1 1/2 teaspoons coconut sugar or turbinado (raw) sugar or brown sugar',
'1 tablespoon tamari or soy sauce***',
'2 teaspoons rice vinegar or fresh lime juice',
'Garnishes/sides: handful of chopped fresh basil or cilantro, optional red pepper flakes, optional sriracha or chili garlic sauce']
scraper.instructions()
'To cook the rice, bring a large pot of water to boil. Add the rinsed rice and continue boiling for 30 minutes, reducing heat as necessary to prevent overflow. Remove from heat, drain the rice and return the rice to pot. Cover and let the rice rest for 10 minutes or longer, until you’re ready to serve. Just before serving, season the rice to taste with salt and fluff it with a fork.\nTo make the curry, warm a large skillet with deep sides over medium heat. Once it’s hot, add the oil. Add the onion and a sprinkle of salt and cook, stirring often, until the onion has softened and is turning translucent, about 5 minutes. Add the ginger and garlic and cook until fragrant, about 30 seconds, while stirring continuously.\nAdd the bell peppers and carrots. Cook until the bell peppers are fork-tender, 3 to 5 more minutes, stirring occasionally. Then add the curry paste and cook, stirring often, for 2 minutes.\nAdd the coconut milk, water, kale and sugar, and stir to combine. Bring the mixture to a simmer over medium heat. Reduce heat as necessary to maintain a gentle simmer and cook until the peppers, carrots and kale have softened to your liking, about 5 to 10 minutes, stirring occasionally.\nRemove the pot from the heat and season with tamari and rice vinegar. Add salt (I added 1/4 teaspoon for optimal flavor), to taste. If the curry needs a little more punch, add 1/2 teaspoon more tamari, or for more acidity, add 1/2 teaspoon more rice vinegar. Divide rice and curry into bowls and garnish with chopped cilantro and a sprinkle of red pepper flakes, if you’d like. If you love spicy curries, serve with sriracha or chili garlic sauce on the side.'
scraper.nutrients()
{'calories': '340 calories',
'sugarContent': '9.3 g',
'sodiumContent': '473.3 mg',
'fatContent': '11.3 g',
'saturatedFatContent': '8 g',
'transFatContent': '0 g',
'carbohydrateContent': '56.3 g',
'fiberContent': '5.6 g',
'proteinContent': '8.3 g',
'cholesterolContent': '0 mg'}
6.3.14. Parsera: Natural Language Web Scraping with LLMs#
Show code cell content
!pip install parsera
Show code cell content
!playwright install
Writing and maintaining web scraping code requires constant updates due to changing HTML structures and complex selectors, which results in brittle code and frequent breakages.
With Parsera, you can scrape websites by simply describing what data you want to extract in plain language, letting LLMs handle the complexity of finding the right elements.
Here’s an example that scrapes GitHub’s trending Python repositories page to collect:
Repository names
Repository owners
Star counts
Fork counts
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY_HERE"
from parsera import Parsera
from pprint import pprint
url = "https://github.com/trending/python?since=daily"
elements = {
"Repository": "Name of the repository",
"Owner": "Owner of the repository",
"Stars": "Number of stars",
"Forks": "Number of forks",
}
scraper = Parsera()
result = scraper.run(url=url, elements=elements)
pprint(result)
[{'Forks': '272', 'Owner': 'DS4SD', 'Repository': 'docling', 'Stars': '5,264'},
{'Forks': '2,502',
'Owner': 'mingrammer',
'Repository': 'diagrams',
'Stars': '38,714'},
{'Forks': '3,883',
'Owner': 'All-Hands-AI',
'Repository': 'OpenHands',
'Stars': '34,095'},
{'Forks': '7,288',
'Owner': 'frappe',
'Repository': 'erpnext',
'Stars': '21,616'},
{'Forks': '7,249',
'Owner': 'abi',
'Repository': 'screenshot-to-code',
'Stars': '58,574'},
{'Forks': '46,154',
'Owner': 'donnemartin',
'Repository': 'system-design-primer',
'Stars': '274,420'},
{'Forks': '1,259',
'Owner': 'Cinnamon',
'Repository': 'kotaemon',
'Stars': '16,395'},
{'Forks': '927',
'Owner': 'vanna-ai',
'Repository': 'vanna',
'Stars': '11,585'},
{'Forks': '1,792',
'Owner': 'roboflow',
'Repository': 'supervision',
'Stars': '24,005'},
{'Forks': '323',
'Owner': 'instructlab',
'Repository': 'instructlab',
'Stars': '899'},
{'Forks': '1,006',
'Owner': 'VikParuchuri',
'Repository': 'marker',
'Stars': '17,520'},
{'Forks': '12,228',
'Owner': 'geekcomputers',
'Repository': 'Python',
'Stars': '31,470'},
{'Forks': '2,820',
'Owner': 'Azure',
'Repository': 'azure-sdk-for-python',
'Stars': '4,610'},
{'Forks': '1,589',
'Owner': 'BerriAI',
'Repository': 'litellm',
'Stars': '13,574'},
{'Forks': '74',
'Owner': 'homebrewltd',
'Repository': 'ichigo',
'Stars': '1,616'},
{'Forks': '4,348',
'Owner': 'd2l-ai',
'Repository': 'd2l-en',
'Stars': '23,811'},
{'Forks': '2,456', 'Owner': 'psf', 'Repository': 'black', 'Stars': '38,902'}]
6.3.15. Generating Synthetic Tabular Data with TabGAN#
Show code cell content
!pip install tabgan
Limited, imbalanced, or missing data in tabular datasets can lead to poor model performance and biased predictions.
To address this issue, TabGAN provides a solution by generating synthetic tabular data that maintains the statistical properties and relationships of the original dataset.
In this example, we will demonstrate how to use TabGAN to generate high-quality synthetic data using different generators (GAN, Diffusion, or LLM-based).
First, we create random input data:
from tabgan.sampler import OriginalGenerator, GANGenerator, ForestDiffusionGenerator, LLMGenerator
import pandas as pd
import numpy as np
train = pd.DataFrame(np.random.randint(-10, 150, size=(150, 4)), columns=list("ABCD"))
target = pd.DataFrame(np.random.randint(0, 2, size=(150, 1)), columns=list("Y"))
test = pd.DataFrame(np.random.randint(0, 100, size=(100, 4)), columns=list("ABCD"))
print("Training Data:")
print(train.head())
print("\nTarget Data:")
print(target.head())
print("\nTest Data:")
print(test.head())
Training Data:
A B C D
0 29 135 29 113
1 88 77 28 126
2 135 31 37 137
3 25 138 16 79
4 97 141 120 55
Target Data:
Y
0 0
1 1
2 1
3 0
4 0
Test Data:
A B C D
0 77 98 56 15
1 80 16 38 7
2 63 87 57 50
3 17 11 64 27
4 9 29 85 75
Next, we use the OriginalGenerator to generate synthetic data:
new_train1, new_target1 = OriginalGenerator().generate_data_pipe(train, target, test)
print("Training Data:")
print(new_train1.head())
print("\nTarget Data:")
print(new_target1.head())
Training Data:
A B C D
0 38 46 34 69
1 38 46 34 69
2 38 46 34 69
3 38 46 34 69
4 38 46 34 69
Target Data:
0 1
1 1
2 1
3 1
4 1
Name: Y, dtype: int64
The generate_data_pipe method takes in the following parameters:
train_df: The training dataframe.target: The target variable for the training dataset.test_df: The testing dataframe.deep_copy: A boolean indicating whether to make a deep copy of the input dataframes. Default isTrue.only_adversarial: A boolean indicating whether to only perform adversarial filtering on the training dataframe. Default isFalse.use_adversarial: A boolean indicating whether to perform adversarial filtering on the generated data. Default isTrue.only_generated_data: A boolean indicating whether to return only the generated data. Default isFalse.
Alternatively, we can use the GANGenerator to generate synthetic data:
new_train2, new_target2 = GANGenerator(
gen_params={
"batch_size": 500, # Process data in batches of 500 samples at a time
"epochs": 10, # Train for a maximum of 10 epochs
"patience": 5 # Stop early if there is no improvement for 5 epochs
}
).generate_data_pipe(train, target, test)
print("Training Data:")
print(new_train2.head())
print("\nTarget Data:")
print(new_target2.head())
Training Data:
A B C D
0 72 33 87 83
1 80 16 81 84
2 95 36 92 89
3 88 39 68 91
4 3 0 74 98
Target Data:
0 1
1 0
2 1
3 0
4 0
Name: Y, dtype: int64
The GANGenerator takes in the following parameters:
gen_x_times: A float indicating how much data to generate. Default is1.1.cat_cols: A list of categorical columns. Default isNone.bot_filter_quantile: A float indicating the bottom quantile for post-processing filtering. Default is0.001.top_filter_quantile: A float indicating the top quantile for post-processing filtering. Default is0.999.is_post_process: A boolean indicating whether to perform post-processing filtering. Default isTrue.adversarial_model_params: A dictionary of parameters for the adversarial filtering model. Default isNone.pregeneration_frac: A float indicating the fraction of data to generate before post-processing filtering. Default is2.gen_params: A dictionary of parameters for the GAN training process. Default isNone.