Build Pipelines
5. Build Pipelines#
As a data scientist, why should you care about optimizing your data science workflow? Let’s start with an example of a basic data science project.
Imagine you were working with an Iris dataset. You started with building functions to process your data.
from typing import Any, Dict, List
import pandas as pd
def load_data(path: str) -> pd.DataFrame:
...
def get_classes(data: pd.DataFrame, target_col: str) -> List[str]:
"""Task for getting the classes from the Iris data set."""
...
def encode_categorical_columns(data: pd.DataFrame, target_col: str) -> pd.DataFrame:
"""Task for encoding the categorical columns in the Iris data set."""
...
def split_data(data: pd.DataFrame, test_data_ratio: float, classes: list) -> Dict[str, Any]:
"""Task for splitting the classical Iris data set into training and test
sets, each split into features and labels.
"""
...
After defining the functions, you execute them.
# Define parameters
target_col = 'species'
test_data_ratio = 0.2
# Run functions
data = load_data(path="data/raw/iris.csv")
categorical_columns = encode_categorical_columns(data=data, target_col=target_col)
classes = get_classes(data=data, target_col=target_col)
train_test_dict = split_data(data=categorical_columns,
test_data_ratio=test_data_ratio,
classes=classes)
Your code ran fine, and you saw nothing wrong with the output, so you think the workflow is good enough. However, there can be many disadvantages with a linear workflow like above.

The disadvantages are:
If there is an error in the function
get_classes, the output produced by the functionencode_categorical_columnswill be lost, and the workflow will need to start from the beginning. This can be frustrating if it takes a long time to execute the functionencode_categorical_columns.
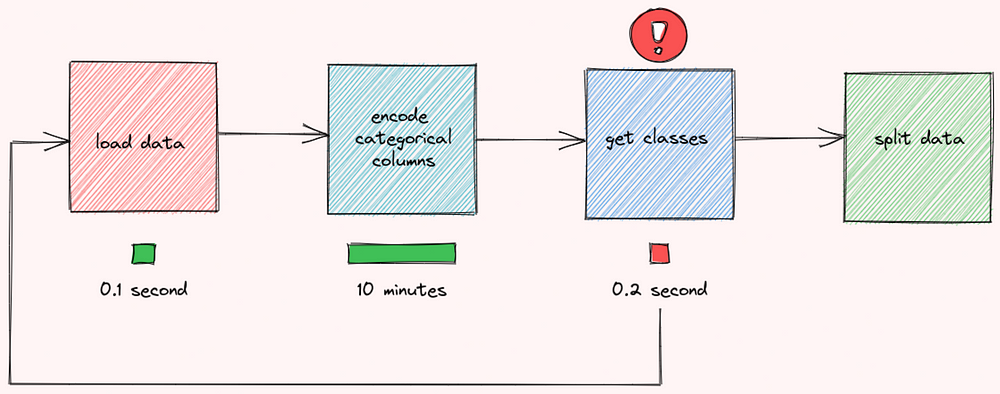
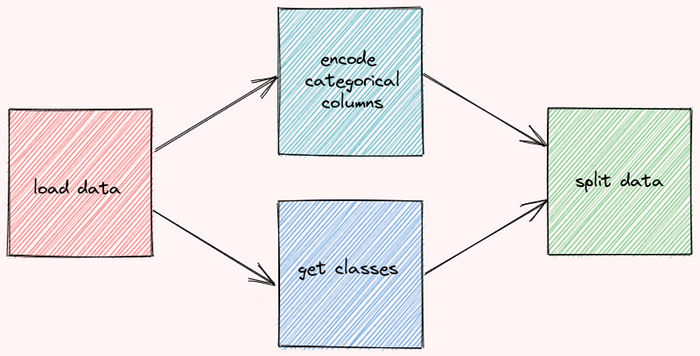
Since the functions
encode_categorical_columnsandget_classesare not dependent on each other, they can be executed at the same time to save time:
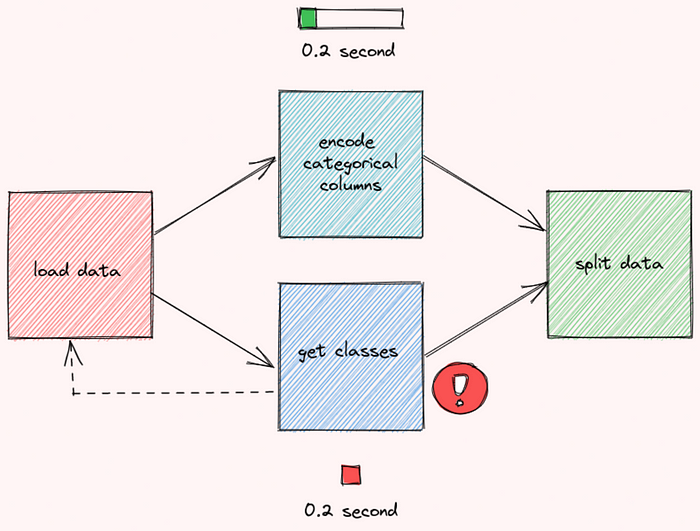
Running the functions this way can also prevent wasting unnecessary time on functions that don’t work. If there is an error in the function get_classes , the workflow will restart right away without waiting for the function encode_categorical_columns to finish.
Now, you might agree with me that it is important to optimize the workflow of different functions. However, it can be a lot of works to manually manage the workflow.
Is there a way that you can automatically optimize the workflow by adding only several lines of code? That is when orchestration libraries come in handy.