khuyentran1401.github.io
My Collection of Data Science Articles
I like to read a variety of data science articles to expand my knowledge as well as apply it for real-world problems. But it is extremely difficult to remember every article. Thus, I want to organize the articles so that it is easier for me to refer back to them in the future.
In particular, I want to sort, summarize, and write down key takeaways from the article. I found Github issues is a perfect tool for this. I created this machine-learning-articles repo to organize my data science articles with Github issues.

Check out the page for the repo here. Contributions are welcomed.
My Data Science Articles
Collection of useful data science topics along with code and articles in my data science blog

Portfolio
Natural Language Processing
Explore and Visualize my LinkedIn Network with Python and Sentiment Analysis

As an active user on LinkedIn with more than 500 connections, I was curious about the statistics of people in my network as well as the messages I received over the last 2 years. This project applies visualization and sentiment analysis to analyze my network and LinkedIn messages.
Create an App to Predict Sentiment and Word Similaries
Utilize spaCy and Streamlit to create an app to predict sentiment and word similaries


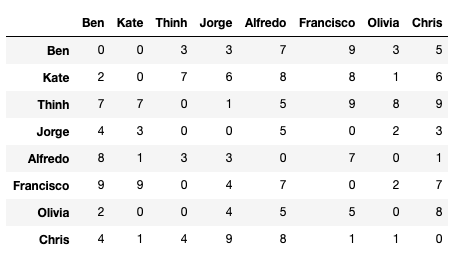
Predict Gender and Location of Author in Twitter
Identity gender and language variety in Twitter in English. In specific, we want to classify between male and female and their locations including Australia, Canada, Great Britain, Ireland, New Zealand, United States.

Real or Not - Predict which Tweets are about Real Disasters
Predict whether a tweet is about a disaster ot not. Preprocess with NLTK (Natural Language Toolkit) and perform model training with various models and techniques including: Tf-Idf, Tf-Idf with Ngrams (words and characters), SelectKbest, Binary Vectorizer, Word2Vec, Neural Network and Convolutional Neural Network with PyTorch. Achieve a f1-score of 80%.

Computer Vision
Create an App to Classify Dogs Using fastai and Streamlit
This is a simple app to classify dogs using fastai and streamlit. The app is deployed using Streamlit Sharing. Click here to view and play with the app.

Data Analysis
I Scraped more than 1k Top Machine Learning Github Profiles and this is what I Found
When searching the keyword “machine learning” on Github, I found 246,632 machine learning repositories. Since these are top repositories in machine learning, I expect the owners and the contributors of these repositories to be experts or competent in machine learning. Thus, I decided to extract the profiles of these users to gain some interesting insights into their background as well as statistics.

What I Learned from Scraping 15k Data Science Articles on Medium
As a data science writer, I wonder:
- What factors make an article receive a high number of claps
- What is the average number of claps? Some articles I came across have 100 or even 1000 claps. Is that a typical number of claps for a Data Science article?
- Which titles are most used by data science articles?
- What is the ideal reading time for a good article?
- Will publishing on the weekdays give more claps than the weekends?
To answer these questions, I scraped all data science articles on Medium published within the last year.

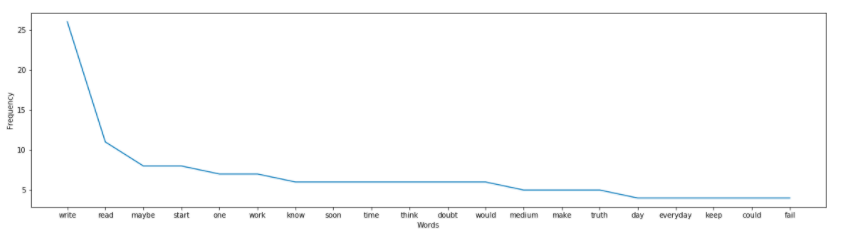
Find most Frequent Words in Articles
Description: Extract the text from an article using Python Article Library and use NLTK (Natural Language Processing Toolkit) to preprocess the text and extract the most common words in the article.
Tools: Newspaper3k (Python libary for article scraping), NLTK (Natural Language Processing Toolkit)
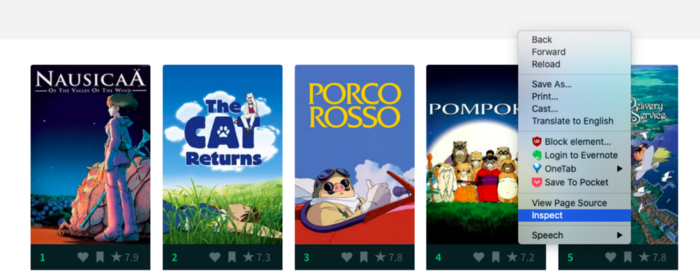
Analyse Sentiment of Ghibli Movie Database
Description: Extract data from Ghibli movie database, preprocess the data, and perform sentiment analysis to predict if the movie is negative, positive, or neutral
Tools: Beautiful Soup (a Python library for scraping), NLTK (Natural Language Processing Toolkit), Scikit-learn, Numpy, Pandas
Find the Correlation between Depression Rate and Sunshine Hours
Motivation: My roomate and I were discussing about the correlation between the sun and depression. To prove my point that less sun is correlated to depression rate, I gather the data to support my hypothesis.
Tools: Beautiful Soup, Numpy, Pandas, Matplotlib

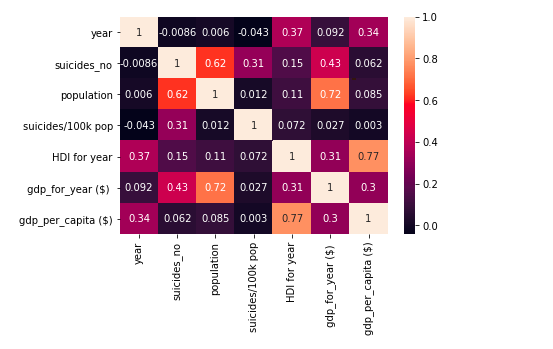
Determine Predictors of Suicide
Description: Find the predictors of suicide among different countries, years, sex, generation, and age group. Apply multiple preprocesing techniques, incorporate geopandas to visualize the distribution on the map, and utilize three different machine learning models with accurate metrics of measuring.
Analyze World Happiness Report
Description: Explore the predictors of happiness among countries in the world
Visualization Techniques: Countplot, Jointplot, Heatmap
Mathematical Programming
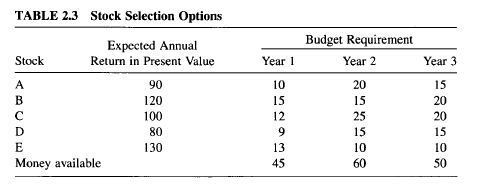
How to choose stocks to invest in with Python
Decide which stocks to invest in each year so as to maximize the total returns using mathematical programming.
How to Find a Best Match with Python
Split employees into groups of 2 people while maximizing the preference of each employee.